Predominio diagonal. Sistemas con dominancia diagonal Reducir la matriz a dominancia diagonal
Definición.
Llamemos a un sistema sistema con dominancia de filas diagonales si los elementos de la matrizsatisfacer las desigualdades:
 ,
,

Las desigualdades significan que en cada fila de la matriz  el elemento diagonal está resaltado: su módulo es mayor que la suma de los módulos de todos los demás elementos de la misma fila.
el elemento diagonal está resaltado: su módulo es mayor que la suma de los módulos de todos los demás elementos de la misma fila.
Teorema
Un sistema con dominancia diagonal siempre tiene solución y, además, de forma única.
Considere el sistema homogéneo correspondiente:
 ,
,

Supongamos que tiene una solución no trivial  , Deje que el componente de módulo más grande de esta solución corresponda al índice
, Deje que el componente de módulo más grande de esta solución corresponda al índice  , es decir.
, es decir.
 ,
, ,
,
 .
.
vamos a escribirlo  aésima ecuación del sistema en la forma
aésima ecuación del sistema en la forma

y toma el módulo de ambos lados de esta igualdad. Como resultado obtenemos:
 .
.
Reducir la desigualdad en un factor  , que según nosotros no es igual a cero, llegamos a una contradicción con la desigualdad que expresa dominancia diagonal. La contradicción resultante nos permite hacer tres afirmaciones en secuencia:
, que según nosotros no es igual a cero, llegamos a una contradicción con la desigualdad que expresa dominancia diagonal. La contradicción resultante nos permite hacer tres afirmaciones en secuencia:

El último de ellos significa que la demostración del teorema está completa.
Sistemas con matriz tridiagonal. Método de ejecución.
Al resolver muchos problemas, uno tiene que lidiar con sistemas de ecuaciones lineales de la forma:
, ,
,
 ,
, ,
,
donde estan los coeficientes  , lados derechos
, lados derechos 
 conocido junto con los números
conocido junto con los números  Y
Y  . Las relaciones adicionales a menudo se denominan condiciones de frontera del sistema. En muchos casos pueden ser más complejos. Por ejemplo:
. Las relaciones adicionales a menudo se denominan condiciones de frontera del sistema. En muchos casos pueden ser más complejos. Por ejemplo:
 ;
;
 ,
,
Dónde  - números dados. Sin embargo, para no complicar la presentación, nos limitaremos a la forma más sencilla de condiciones adicionales.
- números dados. Sin embargo, para no complicar la presentación, nos limitaremos a la forma más sencilla de condiciones adicionales.
Aprovechando que los valores  Y
Y  dado, reescribimos el sistema en la forma:
dado, reescribimos el sistema en la forma:

La matriz de este sistema tiene una estructura tridiagonal:

Esto simplifica significativamente la solución del sistema gracias a un método especial llamado método de barrido.
El método se basa en el supuesto de que las incógnitas desconocidas  Y
Y  conectado por relación de recurrencia
conectado por relación de recurrencia
 ,
, .
.
Aquí las cantidades  ,
, , llamados coeficientes de ejecución, están sujetos a determinación en función de las condiciones del problema. De hecho, tal procedimiento significa reemplazar la definición directa de incógnitas.
, llamados coeficientes de ejecución, están sujetos a determinación en función de las condiciones del problema. De hecho, tal procedimiento significa reemplazar la definición directa de incógnitas.  la tarea de determinar los coeficientes de ejecución y luego calcular los valores basados en ellos
la tarea de determinar los coeficientes de ejecución y luego calcular los valores basados en ellos  .
.
Para implementar el programa descrito, lo expresamos usando la relación  a través de
a través de  :
:
y sustituir  Y
Y  , expresado a través de
, expresado a través de  , en las ecuaciones originales. Como resultado obtenemos:
, en las ecuaciones originales. Como resultado obtenemos:
 .
.
Las últimas relaciones seguramente quedarán satisfechas y, además, independientemente de la solución, si exigimos que cuando  había igualdades:
había igualdades:

A partir de aquí se siguen las relaciones de recurrencia para los coeficientes de barrido:
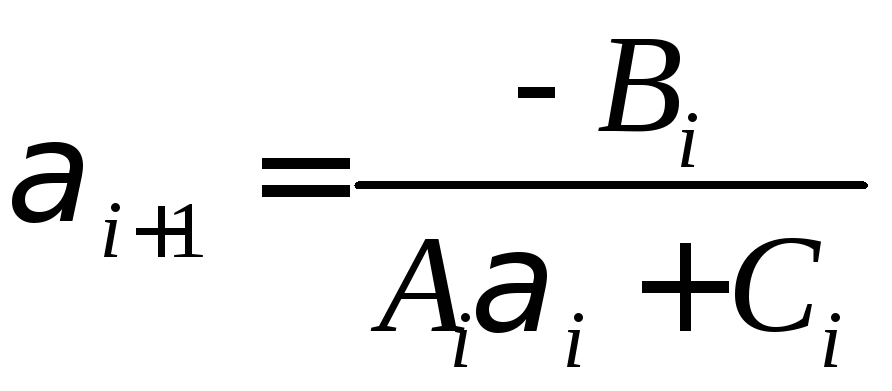 ,
, ,
, .
.
Condición de límite izquierdo  y proporción
y proporción  son consistentes si ponemos
son consistentes si ponemos
 .
.
Otros valores de los coeficientes de barrido.  Y
Y  encontramos desde, que completa la etapa de cálculo de los coeficientes de ejecución.
encontramos desde, que completa la etapa de cálculo de los coeficientes de ejecución.
 .
.
Desde aquí puedes encontrar las incógnitas restantes.  en el proceso de barrido hacia atrás utilizando la fórmula de recurrencia.
en el proceso de barrido hacia atrás utilizando la fórmula de recurrencia.
El número de operaciones necesarias para resolver un sistema general mediante el método gaussiano aumenta al aumentar  proporcionalmente
proporcionalmente  . El método de barrido se reduce a dos ciclos: primero, los coeficientes de barrido se calculan mediante fórmulas, luego, utilizándolas, se encuentran los componentes de la solución del sistema mediante fórmulas recurrentes.
. El método de barrido se reduce a dos ciclos: primero, los coeficientes de barrido se calculan mediante fórmulas, luego, utilizándolas, se encuentran los componentes de la solución del sistema mediante fórmulas recurrentes.  . Esto significa que a medida que aumenta el tamaño del sistema, el número de operaciones aritméticas aumentará proporcionalmente.
. Esto significa que a medida que aumenta el tamaño del sistema, el número de operaciones aritméticas aumentará proporcionalmente.  , pero no
, pero no  . Por tanto, el método de barrido, dentro del ámbito de su posible aplicación, es significativamente más económico. A esto hay que sumar la especial sencillez de su implementación software en un ordenador.
. Por tanto, el método de barrido, dentro del ámbito de su posible aplicación, es significativamente más económico. A esto hay que sumar la especial sencillez de su implementación software en un ordenador.
En muchos problemas aplicados que conducen a SLAE con una matriz tridiagonal, sus coeficientes satisfacen las desigualdades:
 ,
,
que expresan la propiedad de dominancia diagonal. En particular, nos encontraremos con tales sistemas en los capítulos tercero y quinto.
Según el teorema de la sección anterior, una solución para tales sistemas siempre existe y es única. Para ellos también es válida una afirmación que es importante para el cálculo real de la solución mediante el método de barrido.
Lema
Si para un sistema con una matriz tridiagonal se cumple la condición de dominancia diagonal, entonces los coeficientes de barrido satisfacen las desigualdades:
 .
.
Realizaremos la prueba por inducción. De acuerdo a  , es decir, cuando
, es decir, cuando  el enunciado del lema es verdadero. Supongamos ahora que es cierto para
el enunciado del lema es verdadero. Supongamos ahora que es cierto para  y considerar
y considerar  :
:
 .
.
Entonces, la inducción de  A
A  está justificado, lo que completa la prueba del lema.
está justificado, lo que completa la prueba del lema.
Desigualdad para coeficientes de barrido.  hace que la carrera sea estable. De hecho, supongamos que el componente de la solución
hace que la carrera sea estable. De hecho, supongamos que el componente de la solución  Como resultado del procedimiento de redondeo, se calculó con algún error. Luego, al calcular el siguiente componente
Como resultado del procedimiento de redondeo, se calculó con algún error. Luego, al calcular el siguiente componente  Según la fórmula recurrente, este error, gracias a la desigualdad, no aumentará.
Según la fórmula recurrente, este error, gracias a la desigualdad, no aumentará.
Definición.
Llamemos a un sistema sistema con dominancia de filas diagonales si los elementos de la matrizsatisfacer las desigualdades:
 ,
,

Las desigualdades significan que en cada fila de la matriz  el elemento diagonal está resaltado: su módulo es mayor que la suma de los módulos de todos los demás elementos de la misma fila.
el elemento diagonal está resaltado: su módulo es mayor que la suma de los módulos de todos los demás elementos de la misma fila.
Teorema
Un sistema con dominancia diagonal siempre tiene solución y, además, de forma única.
Considere el sistema homogéneo correspondiente:
 ,
,

Supongamos que tiene una solución no trivial 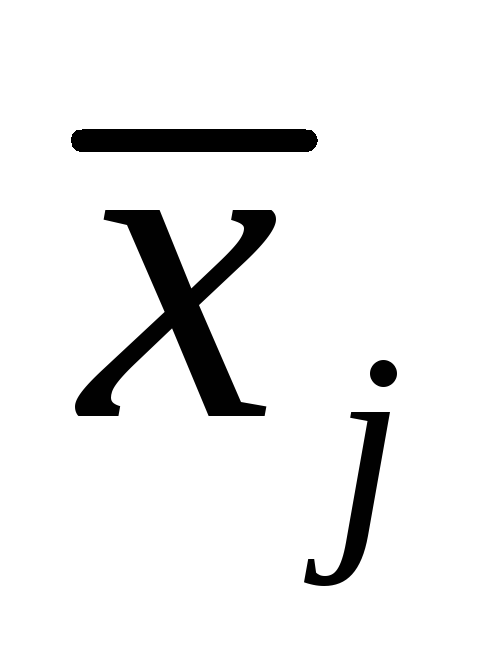 , Deje que el componente de módulo más grande de esta solución corresponda al índice
, Deje que el componente de módulo más grande de esta solución corresponda al índice  , es decir.
, es decir.
 ,
,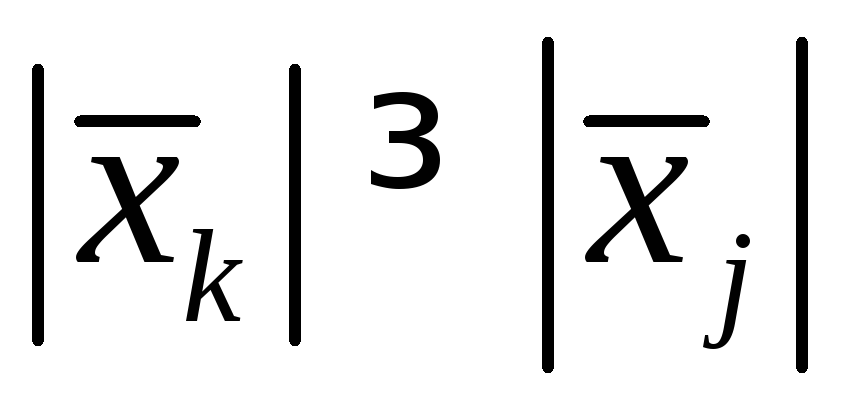 ,
,
 .
.
vamos a escribirlo  aésima ecuación del sistema en la forma
aésima ecuación del sistema en la forma

y toma el módulo de ambos lados de esta igualdad. Como resultado obtenemos:
 .
.
Reducir la desigualdad en un factor 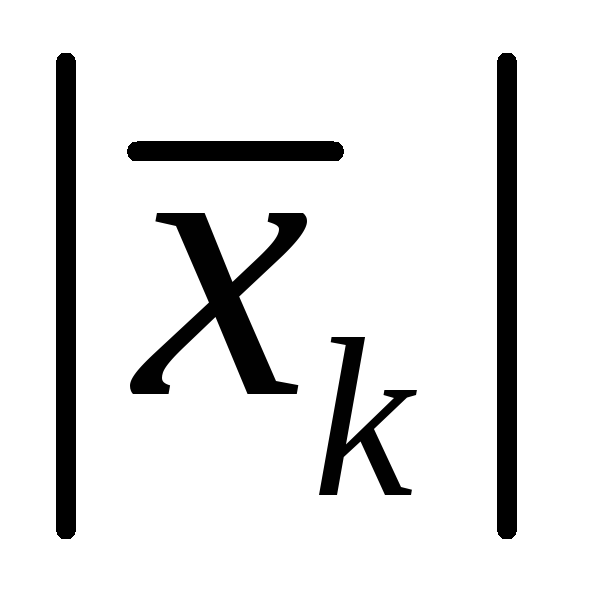 , que según nosotros no es igual a cero, llegamos a una contradicción con la desigualdad que expresa dominancia diagonal. La contradicción resultante nos permite hacer tres afirmaciones en secuencia:
, que según nosotros no es igual a cero, llegamos a una contradicción con la desigualdad que expresa dominancia diagonal. La contradicción resultante nos permite hacer tres afirmaciones en secuencia:

El último de ellos significa que la demostración del teorema está completa.
Sistemas con matriz tridiagonal. Método de ejecución.
Al resolver muchos problemas, uno tiene que lidiar con sistemas de ecuaciones lineales de la forma:
, ,
,
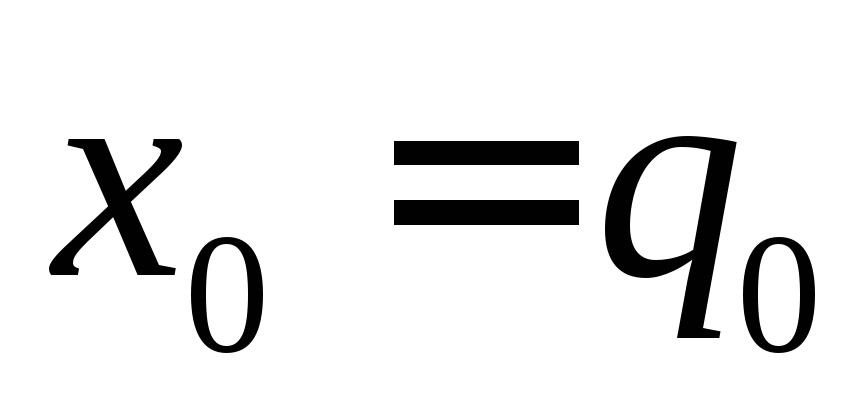 ,
,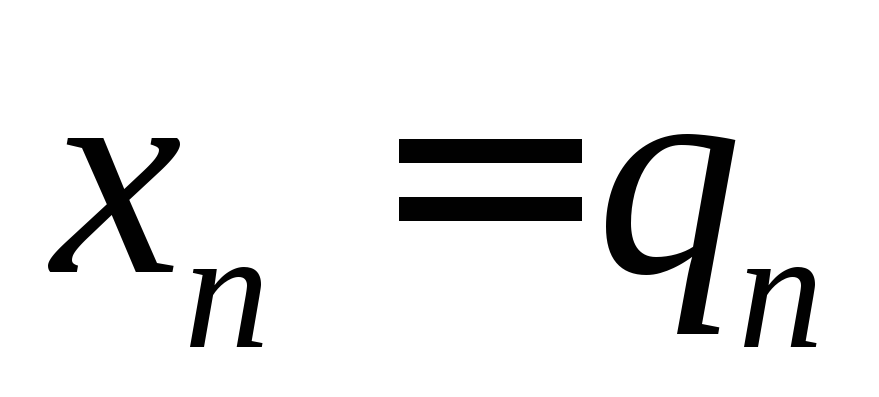 ,
,
donde estan los coeficientes  , lados derechos
, lados derechos 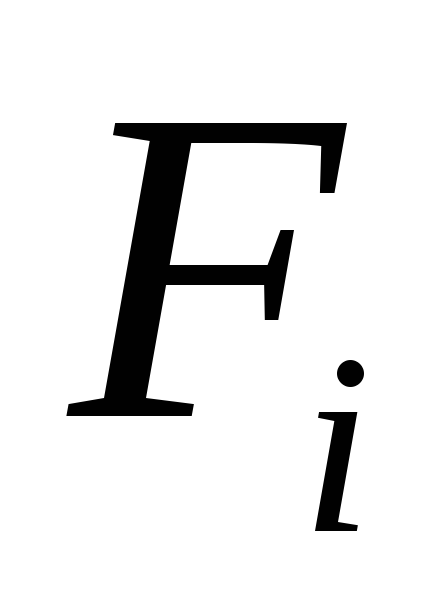
 conocido junto con los números
conocido junto con los números  Y
Y  . Las relaciones adicionales a menudo se denominan condiciones de frontera del sistema. En muchos casos pueden ser más complejos. Por ejemplo:
. Las relaciones adicionales a menudo se denominan condiciones de frontera del sistema. En muchos casos pueden ser más complejos. Por ejemplo:
 ;
;
 ,
,
Dónde  - números dados. Sin embargo, para no complicar la presentación, nos limitaremos a la forma más sencilla de condiciones adicionales.
- números dados. Sin embargo, para no complicar la presentación, nos limitaremos a la forma más sencilla de condiciones adicionales.
Aprovechando que los valores  Y
Y  dado, reescribimos el sistema en la forma:
dado, reescribimos el sistema en la forma:

La matriz de este sistema tiene una estructura tridiagonal:

Esto simplifica significativamente la solución del sistema gracias a un método especial llamado método de barrido.
El método se basa en el supuesto de que las incógnitas desconocidas  Y
Y  conectado por relación de recurrencia
conectado por relación de recurrencia
 ,
, .
.
Aquí las cantidades  ,
, , llamados coeficientes de ejecución, están sujetos a determinación en función de las condiciones del problema. De hecho, tal procedimiento significa reemplazar la definición directa de incógnitas.
, llamados coeficientes de ejecución, están sujetos a determinación en función de las condiciones del problema. De hecho, tal procedimiento significa reemplazar la definición directa de incógnitas. 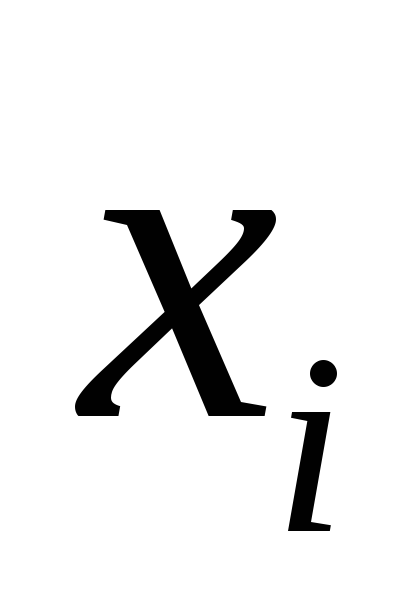 la tarea de determinar los coeficientes de ejecución y luego calcular los valores basados en ellos
la tarea de determinar los coeficientes de ejecución y luego calcular los valores basados en ellos  .
.
Para implementar el programa descrito, lo expresamos usando la relación 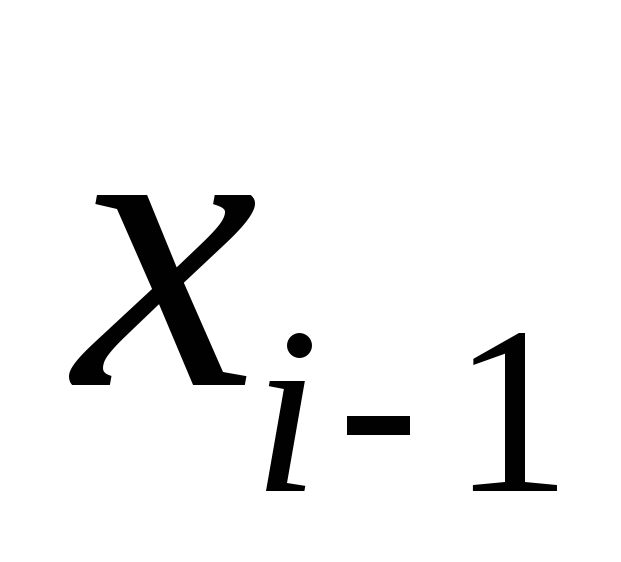 a través de
a través de 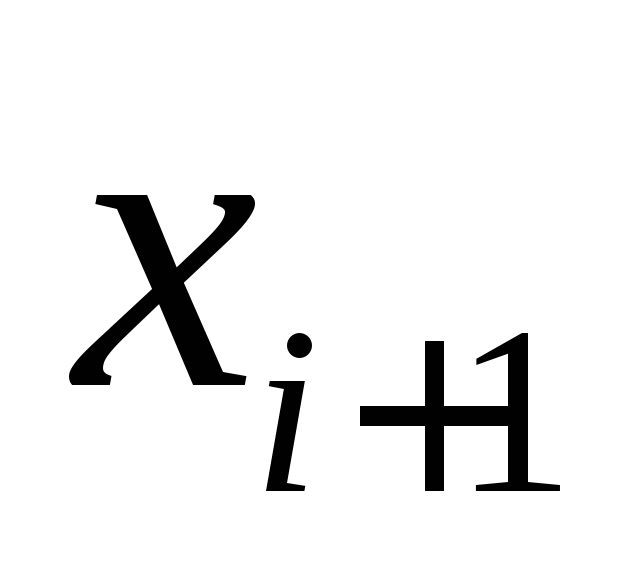 :
:
y sustituir  Y
Y  , expresado a través de
, expresado a través de  , en las ecuaciones originales. Como resultado obtenemos:
, en las ecuaciones originales. Como resultado obtenemos:
 .
.
Las últimas relaciones seguramente quedarán satisfechas y, además, independientemente de la solución, si exigimos que cuando  había igualdades:
había igualdades:

A partir de aquí se siguen las relaciones de recurrencia para los coeficientes de barrido:
 ,
, ,
, .
.
Condición de límite izquierdo  y proporción
y proporción  son consistentes si ponemos
son consistentes si ponemos
 .
.
Otros valores de los coeficientes de barrido.  Y
Y  encontramos desde, que completa la etapa de cálculo de los coeficientes de ejecución.
encontramos desde, que completa la etapa de cálculo de los coeficientes de ejecución.
 .
.
Desde aquí puedes encontrar las incógnitas restantes.  en el proceso de barrido hacia atrás utilizando la fórmula de recurrencia.
en el proceso de barrido hacia atrás utilizando la fórmula de recurrencia.
El número de operaciones necesarias para resolver un sistema general mediante el método gaussiano aumenta al aumentar  proporcionalmente
proporcionalmente  . El método de barrido se reduce a dos ciclos: primero, los coeficientes de barrido se calculan mediante fórmulas, luego, utilizándolas, se encuentran los componentes de la solución del sistema mediante fórmulas recurrentes.
. El método de barrido se reduce a dos ciclos: primero, los coeficientes de barrido se calculan mediante fórmulas, luego, utilizándolas, se encuentran los componentes de la solución del sistema mediante fórmulas recurrentes.  . Esto significa que a medida que aumenta el tamaño del sistema, el número de operaciones aritméticas aumentará proporcionalmente.
. Esto significa que a medida que aumenta el tamaño del sistema, el número de operaciones aritméticas aumentará proporcionalmente.  , pero no
, pero no  . Por tanto, el método de barrido, dentro del ámbito de su posible aplicación, es significativamente más económico. A esto hay que sumar la especial sencillez de su implementación software en un ordenador.
. Por tanto, el método de barrido, dentro del ámbito de su posible aplicación, es significativamente más económico. A esto hay que sumar la especial sencillez de su implementación software en un ordenador.
En muchos problemas aplicados que conducen a SLAE con una matriz tridiagonal, sus coeficientes satisfacen las desigualdades:
 ,
,
que expresan la propiedad de dominancia diagonal. En particular, nos encontraremos con tales sistemas en los capítulos tercero y quinto.
Según el teorema de la sección anterior, una solución para tales sistemas siempre existe y es única. Para ellos también es válida una afirmación que es importante para el cálculo real de la solución mediante el método de barrido.
Lema
Si para un sistema con una matriz tridiagonal se cumple la condición de dominancia diagonal, entonces los coeficientes de barrido satisfacen las desigualdades:
 .
.
Realizaremos la prueba por inducción. De acuerdo a  , es decir, cuando
, es decir, cuando  el enunciado del lema es verdadero. Supongamos ahora que es cierto para
el enunciado del lema es verdadero. Supongamos ahora que es cierto para  y considerar
y considerar  :
:
 .
.
Entonces, la inducción de  A
A 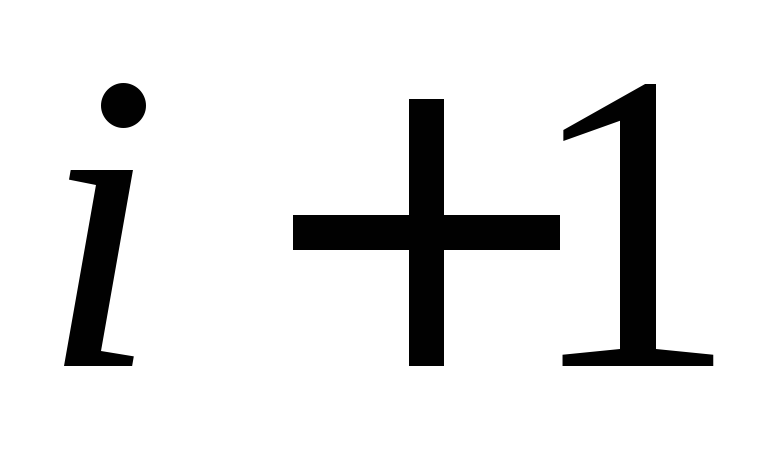 está justificado, lo que completa la prueba del lema.
está justificado, lo que completa la prueba del lema.
Desigualdad para coeficientes de barrido.  hace que la carrera sea estable. De hecho, supongamos que el componente de la solución
hace que la carrera sea estable. De hecho, supongamos que el componente de la solución  Como resultado del procedimiento de redondeo, se calculó con algún error. Luego, al calcular el siguiente componente
Como resultado del procedimiento de redondeo, se calculó con algún error. Luego, al calcular el siguiente componente  Según la fórmula recurrente, este error, gracias a la desigualdad, no aumentará.
Según la fórmula recurrente, este error, gracias a la desigualdad, no aumentará.
UNIVERSIDAD ESTATAL DE SAN PETERSBURGO
Facultad de Matemática Aplicada – Procesos de Control
A.P.IVANOV
TALLER DE MÉTODOS NUMÉRICOS
SISTEMAS DE RESOLUCIÓN DE ECUACIONES ALGEBRAICAS LINEALES
Pautas
San Petersburgo
CAPÍTULO 1. INFORMACIÓN DE RESPALDO
El manual metodológico proporciona una clasificación de métodos para la resolución de SLAE y algoritmos para su aplicación. Los métodos se presentan en una forma que permite su uso sin recurrir a otras fuentes. Se supone que la matriz del sistema no es singular, es decir det A 6= 0.
§1. Normas de vectores y matrices.
Recordemos que un espacio lineal Ω de elementos x se llama normalizado si en él se introduce una función k · kΩ, definida para todos los elementos del espacio Ω y que satisface las condiciones:
1. kxk Ω ≥ 0, y kxkΩ = 0 x = 0Ω;
2. kλxk Ω = |λ| · kxkΩ;
3. kx + yk Ω ≤ kxkΩ + kykΩ .
En el futuro acordaremos denotar vectores con letras latinas minúsculas, y los consideraremos vectores de columna, con letras latinas grandes denotaremos matrices y con letras griegas denotaremos cantidades escalares (conservando las letras i, j, k, l, m, n para números enteros).
Las normas vectoriales más utilizadas incluyen las siguientes:
|xi |; |
|
1. kxk1 = |
|
2. kxk2 = u x2 ; t
3. kxk∞ = maxi |xi |.
Tenga en cuenta que todas las normas en el espacio Rn son equivalentes, es decir, Dos normas cualesquiera kxki y kxkj están relacionadas por:
αij kxkj ≤ kxki ≤ βij kxkj ,
k k ≤ k k ≤ ˜ k k
α˜ ij x i x j β ij x i,
además, αij , βij , α˜ij , βij no dependen de x. Además, en un espacio de dimensión finita dos normas cualesquiera son equivalentes.
El espacio de matrices con las operaciones de suma y multiplicación por un número introducidas naturalmente forman un espacio lineal en el que el concepto de norma se puede introducir de muchas maneras. Sin embargo, la mayoría de las veces se consideran las llamadas normas subordinadas, es decir, normas relacionadas con las normas de los vectores por las relaciones:
Al marcar las normas subordinadas de las matrices con los mismos índices que las normas correspondientes de los vectores, podemos establecer que
k k1 |
|aij|; kak2 |
k∞ |
|||||||||||||
(EN UN); |
|||||||||||||||
Aquí, λi (AT A) denota el valor propio de la matriz AT A, donde AT es la matriz transpuesta a A. Además de las tres propiedades principales de la norma mencionadas anteriormente, observamos dos más aquí:
kABk ≤ kAk kBk,
kAxk ≤ kAk kxk,
Además, en la última desigualdad la norma matricial está subordinada a la norma vectorial correspondiente. Aceptaremos utilizar en el futuro sólo las normas de matrices que estén subordinadas a las normas de vectores. Tenga en cuenta que para tales normas se cumple la siguiente igualdad: si E es la matriz identidad, entonces kEk = 1, .
§2. Matrices con dominancia diagonal
Definición 2.1. Una matriz A con elementos (aij )n i,j=1 se llama matriz con dominancia diagonal (valores δ) si se cumplen las desigualdades
|aiii | − |aij | ≥ δ > 0, yo = 1, norte.

§3. Matrices definidas positivas
Definición 3.1. Llamaremos a una matriz simétrica A por
definida positiva si la forma cuadrática xT Ax con esta matriz toma solo valores positivos para cualquier vector x 6= 0.
El criterio para la precisión positiva de una matriz puede ser la positividad de sus valores propios o la positividad de sus menores principales.
§4. Número de condición SLAE
A la hora de resolver cualquier problema, como se sabe, se cometen tres tipos de errores: error fatal, error metodológico y error de redondeo. Consideremos la influencia del error inevitable en los datos iniciales en la solución del SLAE, despreciando el error de redondeo y teniendo en cuenta la ausencia de error metodológico.
La matriz A se conoce exactamente y el lado derecho b contiene un error inamovible δb.
Entonces para el error relativo de la solución kδxk/kxk
No es difícil conseguir un presupuesto: |
|||||||
donde ν(A) = kAkkA−1 k.
El número ν(A) se denomina número de condición del sistema (4.1) (o matriz A). Resulta que ν(A) ≥ 1 para cualquier matriz A. Dado que el valor del número de condición depende de la elección de la norma de la matriz, al elegir una norma específica indexaremos ν(A) en consecuencia: ν1 (A), ν2 (A) o ν ∞(A).
En el caso de ν(A) 1, el sistema (4.1) o matriz A se denomina mal condicionado. En este caso, como se desprende de la estimación.

(4.2), el error al resolver el sistema (4.1) puede resultar inaceptablemente grande. El concepto de aceptabilidad o inaceptabilidad de un error está determinado por el planteamiento del problema.
Para una matriz con dominancia diagonal, es fácil obtener un límite superior para su número de condición. Ocurre
Teorema 4.1. Sea A una matriz con dominancia diagonal de valor δ > 0. Entonces es no singular y ν∞ (A) ≤ kAk∞ /δ.
§5. Un ejemplo de un sistema mal condicionado.
Considere el SLAE (4.1) en el que
−1 |
− 1 . . . |
−1 |
−1 |
|||||||||
−1 |
.. . |
|||||||||||
−1 |
||||||||||||
Este sistema tiene una solución única x = (0, 0, . . . , 0, 1)T. Sea el lado derecho del sistema el error δb = (0, 0, . . . , 0, ε), ε > 0. Entonces
δxn = ε, δxn−1 = ε, δxn−2 = 2 ε, δxn−k = 2 k−1 ε, . . . , δx1 = 2 n−2 ε.
k∞ = |
2 norte − 2 ε, |
k∞ |
k∞ |
|||||||||||||
kk∞ |
||||||||||||||||
Por eso,
ν∞ (A) ≥ kδxk ∞ : kδbk ∞ = 2n−2 . kxk ∞ kbk ∞
Como kAk∞ = n, entonces kA−1 k∞ ≥ n−1 2 n−2 , aunque det(A−1 ) = (det A)−1 = 1. Sea, por ejemplo, n = 102. Entonces ν( A ) ≥ 2100 > 1030 . Además, incluso si ε = 10−15 obtenemos kδxk∞ > 1015. Y todavía
NO SENERACIA DE MATRICES Y PROPIEDAD DE DOMINANCIA DIAGONAL1
© 2013 L. Cvetkovic, V. Kostic, L.A. más corrupto
Liliana Cvetkovic - Profesora, Departamento de Matemáticas e Informática, Facultad de Ciencias, Universidad de Novi Sad, Serbia, Obradovica 4, Novi Sad, Serbia, 21000, correo electrónico: [correo electrónico protegido].
Kostic Vladimir - profesor asistente, doctor, Departamento de Matemáticas e Informática, Facultad de Ciencias, Universidad de Novi Sad, Serbia, Obradovica 4, 21000, Novi Sad, Serbia, correo electrónico: [correo electrónico protegido].
Krukier Lev Abramovich - Doctor en Ciencias Físicas y Matemáticas, Profesor, Jefe del Departamento de Computación de Alto Rendimiento y Tecnologías de la Información y las Comunicaciones, Director del Centro Regional de Informatización del Sur de Rusia de la Universidad Federal del Sur, Stachki Ave. 200/1, edificio. 2, Rostov del Don, 344090, correo electrónico: krukier@sfedu. ru.
Cvetkovic Ljiljana - Profesor, Departamento de Matemáticas e Informática, Facultad de Ciencias, Universidad de Novi Sad, Serbia, D. Obradovica 4, Novi Sad, Serbia, 21000, correo electrónico: [correo electrónico protegido].
Kostic Vladimir - Profesor asistente, Departamento de Matemáticas e Informática, Facultad de Ciencias, Universidad de Novi Sad, Serbia, D. Obradovica 4, Novi Sad, Serbia, 21000, correo electrónico: [correo electrónico protegido].
Krukier Lev Abramovich - Doctor en Ciencias Físicas y Matemáticas, Profesor, Jefe del Departamento de Computación de Alto Rendimiento y Tecnologías de la Información y las Comunicaciones, Director del Centro de Computación de la Universidad Federal del Sur, Stachki Ave, 200/1, bild. 2, Rostov del Don, Rusia, 344090, correo electrónico: krukier@sfedu. ru.
La dominancia diagonal en una matriz es una condición simple que garantiza su no degeneración. Las propiedades de las matrices que generalizan el concepto de dominancia diagonal siempre tienen una gran demanda. Se consideran condiciones del tipo de dominancia diagonal y ayudan a definir subclases de matrices (como las matrices H) que permanecen no degeneradas en estas condiciones. En este trabajo, se construyen nuevas clases de matrices no singulares que conservan las ventajas de la dominancia diagonal, pero permanecen fuera de la clase de matrices H. Estas propiedades son especialmente útiles ya que muchas aplicaciones conducen a matrices de esta clase y ahora se puede ampliar la teoría de la no degeneración de matrices que no son matrices H.
Palabras clave: dominancia diagonal, no degeneración, escalamiento.
Si bien las condiciones simples que garantizan la no singularidad de las matrices siempre son muy bienvenidas, muchas de las cuales pueden considerarse como un tipo de dominancia diagonal tienden a producir subclases de matrices H bien conocidas. En este artículo construimos nuevas clases de matrices no singulares que mantienen la utilidad de la dominancia diagonal, pero mantienen una relación general con la clase de matrices H. Esta propiedad es especialmente favorable, ya que ahora se pueden ampliar muchas aplicaciones que surgen de la teoría de la matriz H.
Palabras clave: dominancia diagonal, no singularidad, técnica de escalamiento.
La solución numérica de problemas de valores en la frontera de la física matemática, por regla general, reduce el problema original a resolver un sistema de ecuaciones algebraicas lineales. Al elegir un algoritmo de solución, ¿necesitamos saber si la matriz original no es singular? Además, la cuestión de la no degeneración de una matriz es relevante, por ejemplo, en la teoría de la convergencia de métodos iterativos, localización de valores propios, al estimar determinantes, raíces de Perron, radio espectral, valores singulares de la matriz, etc
Tenga en cuenta que una de las condiciones más simples, pero extremadamente útiles, que garantiza la no degeneración de una matriz es la conocida propiedad de dominancia diagonal estricta (y sus referencias).
Teorema 1. Sea una matriz A = e Cnxn tal que
s > gramo (a):= S k l, (1)
para todo i e N:= (1,2,...n).
Entonces la matriz A no es degenerada.
Las matrices con la propiedad (1) se denominan matrices con dominancia diagonal estricta
(matrices 8BB). Su generalización natural es la clase de matrices de dominancia diagonal generalizada (vBD), definidas de la siguiente manera:
Definición 1. Una matriz A = [a^ ] e Cxn se llama matriz BB si existe una matriz diagonal no singular W tal que AW es una matriz BB.
Introduzcamos varias definiciones para la matriz.
A = [au] y Sphp.
Definición 2. Matriz (A) = [tuk], definida
(A) = eCn
se llama matriz de comparación de la matriz A.
Definición 3. Matriz A = e C
\üj > 0, i = j
es una matriz M si
aj< 0, i * j,
tapete inverso
ritsa A" >0, es decir, todos sus elementos son positivos.
Es obvio que las matrices de la clase vBB también son matrices no singulares y pueden ser
1Este trabajo fue financiado parcialmente por el Ministerio de Educación y Ciencia de Serbia, subvención 174019, y el Ministerio de Ciencia y Desarrollo Tecnológico de Vojvodina, subvenciones 2675 y 01850.
encontrado en la literatura bajo el nombre de matrices H no degeneradas. Se pueden determinar utilizando la siguiente condición necesaria y suficiente:
Teorema 2. La matriz A \u003d [ay ]e xi
matriz si y solo si su matriz de comparación es una matriz M no singular.
Hasta la fecha, ya se han estudiado muchas subclases de matrices H no singulares, pero todas ellas se consideran desde el punto de vista de generalizaciones de la propiedad de dominancia estrictamente diagonal (véanse también las referencias allí).
Este artículo considera la posibilidad de ir más allá de la clase de matrices H generalizando la clase 8BB de una manera diferente. La idea básica es seguir usando el enfoque de escala, pero con matrices que no sean diagonales.
Considere la matriz A \u003d [ay ] e spxn y el índice
Introduzcamos la matriz.
r (A):= £ a R (A):= £
ßk (A) := £ y yk (A) := aü - ^
Es fácil comprobar que los elementos de la matriz bk abk tienen la siguiente forma:
ßk (A), У k (A), akj,
yo = j = k, yo = j * k,
yo = k, j * k, yo * k, j = k,
A inöaeüiüö neö^äyö.
Si aplicamos el Teorema 1 a la matriz bk ABk1 descrita anteriormente y su transpuesta, obtenemos dos teoremas principales.
Teorema 3. Sea dada cualquier matriz.
A = [ау] e схп con elementos diagonales distintos de cero. Si existe k e N tal que > Tk(A), y para cada g e N\(k),
entonces la matriz A es no singular.
Teorema 4. Sea dada cualquier matriz.
A = [ау] e схп con elementos diagonales distintos de cero. Si existe k e N tal que > Jak(A), y para cada r e N\(k),
Entonces la matriz A no es degenerada. Surge una pregunta natural sobre la conexión entre
matrices de los dos teoremas anteriores: b^ - BOO -matrices (definidas por la fórmula (5)) y
Lk - BOO -matrices (definidas por la fórmula (6)) y la clase de H-matrices. El siguiente ejemplo sencillo deja esto claro.
Ejemplo. Considere las siguientes 4 matrices:
y considere la matriz bk Abk, k e N, similar a la A original. Encontremos las condiciones en las que esta matriz tendrá la propiedad de una matriz SDD (en filas o columnas).
A lo largo del artículo usaremos la notación para r,k eN:= (1,2,.../?)
2 2 1 1 3 -1 1 1 1
" 2 11 -1 2 1 1 2 3
2 1 1 1 2 -1 1 1 5
Teoremas de no degeneración
Todos ellos son no degenerados:
A1 es b - BOO, a pesar de que no es bk - BOO para cualquier k = (1,2,3). Tampoco es una matriz H, ya que (A^ 1 no es no negativo;
A2, debido a la simetría, es simultáneamente bA - BOO y b<2 - БОО, так же как ЬЯ - БОО и
b<3 - БОО, но не является Н-матрицей, так как (А2) вырожденная;
A3 es b9 - BOO, pero no es ninguno de los dos.
Lr - SDD (para k = (1,2,3)), ni una matriz H, ya que (A3 ^ también es singular;
A4 es una matriz H ya que (A^ no es singular y ^A4) 1 > 0, aunque no es ni LR - SDD ni Lk - SDD para cualquier k = (1,2,3).
La figura muestra la relación general entre
Lr - SDD, Lk - SDD y matrices H junto con las matrices del ejemplo anterior.
Relación entre lR - SDD, lC - SDD y
ad min(|au - r (A)|) "
Empezando por la desigualdad
y aplicando este resultado a la matriz bk AB^, obtenemos
Teorema 5. Sea una matriz arbitraria A = [a-- ] e Cxn con elementos diagonales distintos de cero
policías. Si A pertenece a la clase - BOO, entonces
1 + máx^ i*k \acc\
matrices H
Es interesante notar que aunque recibimos
clase de matrices LKk BOO aplicando el Teorema 1 a la matriz obtenida al transponer la matriz Lk AB^1, esta clase no coincide con la clase obtenida aplicando el Teorema 2 a la matriz At.
Introduzcamos algunas definiciones.
Definición 4. La matriz A se llama ( Lk -BOO por filas) si AT ( Lk - BOO ).
Definición 5. La matriz A se llama (bSk -BOO por filas) si AT (bSk - BOO).
Los ejemplos muestran que las clases Shch - BOO,
BC-BOO, (bk - BOO por líneas) y (b^-BOO por líneas) están conectados entre sí. Por tanto, hemos ampliado la clase de matrices H de cuatro formas diferentes.
Aplicación de nuevos teoremas.
Ilustremos la utilidad de los nuevos resultados para estimar la norma C de una matriz inversa.
Para una matriz A arbitraria con dominancia diagonal estricta, el conocido teorema de Varach (VaraI) da la estimación
mín[|pf (A)| - tk (A), min(|yk (A)| - qk(A) - |af (A)|)]" i i (фf ii ii
De manera similar obtenemos el siguiente resultado para las matrices Lk - SDD por columnas.
Teorema 6. Sea una matriz arbitraria A = e cihi con elementos diagonales distintos de cero. Si A pertenece a la clase bk -SDD por columnas, entonces
Ik-lll<_ie#|akk|_
" " millones[|pf (A)| - Rf (AT), mln(|уk (A)|- qk (AT)- |a popa |)]"
La importancia de este resultado es que para muchas subclases de matrices H no singulares existen restricciones de este tipo, pero para aquellas matrices no singulares que no son matrices H este es un problema no trivial. En consecuencia, restricciones de este tipo, como en el teorema anterior, son muy populares.
Literatura
Levy L. Sur le possibilité du l "equlibre electrique C. R. Acad. Paris, 1881. Vol. 93. P. 706-708.
Horn R.A., Johnson C.R. Análisis matricial. Cambridge, 1994. Varga R.S. Gersgorin y sus círculos // Serie Springer en Matemática Computacional. 2004. vol. 36.226 rublos. Berman A., Plemons R.J. Matrices no negativas en las ciencias matemáticas. Serie SIAM Clásicos en Matemática Aplicada. 1994. vol. 9. 340 frotar.
Cvetkovic Lj. Teoría de la matriz H vs. localización de valores propios // Numer. Algor. 2006. vol. 42. págs. 229-245. Cvetkovic Lj., Kostic V., Kovacevic M., Szulc T. Más resultados sobre matrices H y sus complementos de Schur // Appl. Matemáticas. Computadora. 1982. págs. 506-510.
Varah J.M. Un límite inferior para el valor más pequeño de una matriz // Aplicación de álgebra lineal. 1975. vol. 11. págs. 3-5.
Recibido por el editor
tiene la propiedad dominancia diagonal, Si
y al menos una desigualdad es estricta. Si todas las desigualdades son estrictas, entonces se dice que la matriz es tiene estricto dominancia diagonal.
Las matrices diagonalmente dominantes surgen con bastante frecuencia en las aplicaciones. Su principal ventaja es que los métodos iterativos para resolver SLAE con dicha matriz (método de iteración simple, método de Seidel) convergen a una solución exacta que existe únicamente para cualquier lado derecho.
Propiedades
- Una matriz con estricta dominancia diagonal no es singular.
ver también
Escribe una reseña sobre el artículo "Dominancia diagonal"
Extracto que caracteriza el predominio diagonal.
El Regimiento de Húsares de Pavlogrado estaba estacionado a dos millas de Braunau. El escuadrón en el que Nikolai Rostov sirvió como cadete estaba ubicado en el pueblo alemán de Salzenek. Al comandante del escuadrón, el capitán Denisov, conocido en toda la división de caballería con el nombre de Vaska Denisov, se le asignó el mejor apartamento del pueblo. Junker Rostov, desde que alcanzó al regimiento en Polonia, vivió con el comandante del escuadrón.El 11 de octubre, el mismo día en que todo en el apartamento principal se puso de pie con la noticia de la derrota de Mack, en el cuartel general del escuadrón, la vida en el campo continuó tranquilamente como antes. Denisov, que había perdido toda la noche jugando a las cartas, aún no había regresado a casa cuando Rostov regresó temprano en la mañana de buscar comida a caballo. Rostov, con uniforme de cadete, cabalgó hasta el porche, empujó su caballo, con un gesto juvenil y flexible le quitó la pierna, se paró en el estribo, como si no quisiera separarse del caballo, finalmente saltó y gritó al Mensajero.